Deep dive into the clone vs copy question
I came across Naresh Joshi about Copy vs Cloning and was wondering about the performance aspects.
Cloning is known to have issues with final fields.
Also, the fact that the Cloneable interface does not expose the clone method, you need to know the concrete type of the class to call clone.
you can’t write the following code
((Cloneable)o).clone(); // does not work
If the Cloneable interface is broken, the clone mechanism might have some advantages.
By doing memory copy it can be more efficient than field by field copy.
It is highlighted by Josh Bloch, the author of Effective Java quoting Doug Lea:
Doug Lea goes even further. He told me that he doesn’t use clone anymore except to copy arrays. You should use clone to copy arrays, because that’s generally the fastest way to do it. But Doug’s types simply don’t implement Cloneable anymore. He’s given up on it. And I think that’s not unreasonable.
But that was in 2002, is it still the case? Since Java 6 we have Arrays.copyOf how does that compare? What about performance on Object copy?
There is only one way to find out, Let’s benchmark.
TL;DR
Clone is faster for array copy, noticeably on small arrays.- Arrays.copyOf and clone have similar performance.
- use clone for big object more than 8 fields or for object that have expensive calculation on construction i.e. SimpleDateFormat.
- Clone fails the escape analysis, potentially stopping other optimisations to be applied.

Arrays
Update on the array benchmark
Andrei Paguin pointed in the comments that there was an issue in the array benchmark.
replace “size” with “original.length” in Arrays.copyOf() benchmark.
That’s when I realised that yes… that would explain why the jit can figure out that we copy the exact same length. So I change the following and update the conclusions.
Let’s take a first look at clone vs Arrays.copyOf of arrays.
The int array benchmark looks as follows :
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public int[] testCopy() {
return Arrays.copyOf(original, original.length); // use to be size
}
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public int[] testClone() {
return original.clone();
}
We create an array of int with random values and do a clone or Arrays.copyOf.
Note that we return the result of the copy to guarantee that the code will get executed, we will see in the escape analysis part that not returning the array can dramatically impact the benchmark.
On top of int array, there is a version for byte array, long array and Object array.
I use the DONT_INLINE flag to make it easier to analyse the asm generated if needed.
mvn clean install
java -jar target/benchmark.jar -bm avgt -tu ns -rf csv
– SNIP here with updated data –
Objects
Now we will look at cloning object with 4, 8, 16 and 32 fields. The benchmarks looks for 4 fields object is as follows:
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public Object4 testCopy4() {
return new Object4(original);
}
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public Object4 testClone4() {
return original.clone();
}
with 8 fields, 16 fields and 32 fields.
The normalised numbers are as follows:
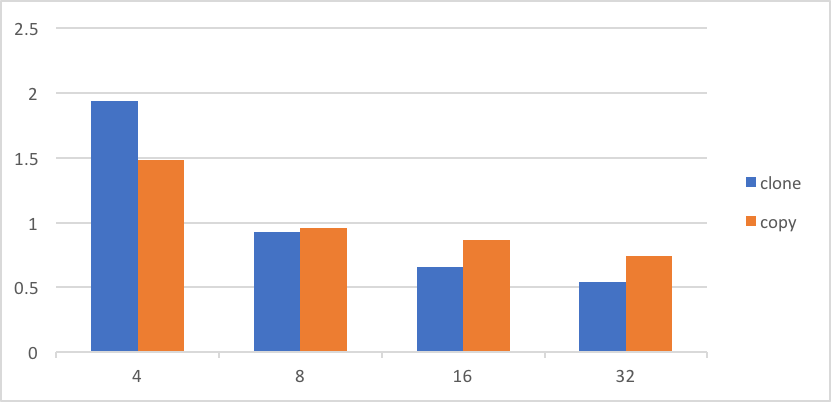
We can see that for small/medium objects - less that 8 fields - clone is not as efficient as copying, but it does start to pay off for bigger objects.
This is not too surprising and from that the jvm code comment:
// TODO: generate fields copies for small objects instead.
Somebody was meant to address that at a later time but never did.
Let’s have a deeper look at the asm for the clone and copy on the 4 fields object.
Asm 4 fields
java -jar target/benchmarks.jar -jvmArgs "-XX:+UnlockDiagnosticVMOptions -XX:+TraceClassLoading -XX:+LogCompilation -XX:+PrintAssembly " -f 1 "Object4"
copy asm
In the testCopy asm, from Line 17 to Line 32 we can see the allocation code.
I added some annotations in the asm starting with **.
0x000000010593d28f: mov 0x60(%r15),%rax
0x000000010593d293: mov %rax,%r10
0x000000010593d296: add $0x20,%r10 ;** allocation size
0x000000010593d29a: cmp 0x70(%r15),%r10
0x000000010593d29e: jae L0001
0x000000010593d2a0: mov %r10,0x60(%r15)
0x000000010593d2a4: prefetchnta 0xc0(%r10)
0x000000010593d2ac: mov $0xf8015eab,%r11d ; {metadata('com/github/arnaudroger/beans/Object4')}
0x000000010593d2b2: movabs $0x0,%r10
0x000000010593d2bc: lea (%r10,%r11,8),%r10
0x000000010593d2c0: mov 0xa8(%r10),%r10
0x000000010593d2c7: mov %r10,(%rax)
0x000000010593d2ca: movl $0xf8015eab,0x8(%rax) ; {metadata('com/github/arnaudroger/beans/Object4')}
0x000000010593d2d1: mov %r12d,0xc(%rax)
0x000000010593d2d5: mov %r12,0x10(%rax)
0x000000010593d2d9: mov %r12,0x18(%rax) ;*new ; - com.github.arnaudroger.Object4CopyVsCloneBenchmark::testCopy4@0 (line 60)
The Line 19 is the allocation size, 32 bytes, 16 bytes for properties + 12 bytes for headers + 4 bytes for alignment. You can check that using jol.
com.github.arnaudroger.beans.Object4 object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 int Object4.f1 N/A
16 4 int Object4.f2 N/A
20 4 int Object4.f3 N/A
24 4 int Object4.f4 N/A
28 4 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
From Line 33 to Line 48 the field by field copy.
L0000: mov 0xc(%rbp),%r11d ;*getfield original4
; - com.github.arnaudroger.Object4CopyVsCloneBenchmark::testCopy4@5 (line 60)
0x000000010593d2e1: mov 0xc(%r12,%r11,8),%r10d ; implicit exception: dispatches to 0x000000010593d322
0x000000010593d2e6: mov %r10d,0xc(%rax) ;*putfield f1
; - com.github.arnaudroger.beans.Object4::<init>@9 (line 12)
; - com.github.arnaudroger.Object4CopyVsCloneBenchmark::testCopy4@8 (line 60)
0x000000010593d2ea: mov 0x10(%r12,%r11,8),%r8d
0x000000010593d2ef: mov %r8d,0x10(%rax) ;*putfield f2
; - com.github.arnaudroger.beans.Object4::<init>@17 (line 13)
; - com.github.arnaudroger.Object4CopyVsCloneBenchmark::testCopy4@8 (line 60)
0x000000010593d2f3: mov 0x14(%r12,%r11,8),%r10d
0x000000010593d2f8: mov %r10d,0x14(%rax) ;*putfield f3
; - com.github.arnaudroger.beans.Object4::<init>@25 (line 14)
; - com.github.arnaudroger.Object4CopyVsCloneBenchmark::testCopy4@8 (line 60)
0x000000010593d2fc: mov 0x18(%r12,%r11,8),%r11d
0x000000010593d301: mov %r11d,0x18(%rax)
clone asm
for the testClone asm we can also see from Line 24 to Line 37 the allocation code.
0x000000010b17da9d: mov 0x60(%r15),%rbx
0x000000010b17daa1: mov %rbx,%r10
0x000000010b17daa4: add $0x20,%r10 ;** allocation size
0x000000010b17daa8: cmp 0x70(%r15),%r10
0x000000010b17daac: jae L0001
0x000000010b17daae: mov %r10,0x60(%r15)
0x000000010b17dab2: prefetchnta 0xc0(%r10)
0x000000010b17daba: mov $0xf8015eab,%r11d ; {metadata('com/github/arnaudroger/beans/Object4')}
0x000000010b17dac0: movabs $0x0,%r10
0x000000010b17daca: lea (%r10,%r11,8),%r10
0x000000010b17dace: mov 0xa8(%r10),%r10
0x000000010b17dad5: mov %r10,(%rbx)
0x000000010b17dad8: movl $0xf8015eab,0x8(%rbx) ; {metadata('com/github/arnaudroger/beans/Object4')}
Which is slightly surprising because in the compilation log

<klass name="java/lang/Object" flags="1" id="729"/>
<method compile_kind="c2n" level="0" bytes="0" name="clone" flags="260" holder="729" id="838" compile_id="167" iicount="512" return="729"/>
<call method="838" inline="1" count="16881" prof_factor="1"/>
<inline_fail reason="native method"/>
<dependency ctxk="833" type="leaf_type"/>
<uncommon_trap reason="unhandled" bci="1" action="none"/>
<intrinsic nodes="69" id="_clone"/>
Object.clone is marked has having failed to inline because it is a “native method”.
clone is an intrinsic and is inlined by inline_native_clone and copy_to_clone.
copy_to_clone generate the allocation and then a long array copy as followed.
The long array copy is doable because objects are 8 bytes aligned in memory.
L0000: lea 0x8(%r12,%r8,8),%rdi ;** src
0x000000010b17dae4: mov %rbx,%rsi ;** dst
0x000000010b17dae7: add $0x8,%rsi ;** add offset
0x000000010b17daeb: mov $0x3,%edx ;** length
0x000000010b17daf0: movabs $0x10aff4780,%r10
0x000000010b17dafa: callq *%r10 ;*invokespecial clone
; - com.github.arnaudroger.beans.Object4::clone@1 (line 28)
; - com.github.arnaudroger.Object4CopyVsCloneBenchmark::testClone4@4 (line 66)
So despite being marked as inline failed, it is fully inlined. It copies from offset 8 bytes and copies 3 long or 24 bytes, the includes 4 bytes for the class metadata, 16 bytes for the 4 ints, and the rest is for alignment.
Impact of Escape Analysis
But because cloning uses memory copy, the instance will fail the escape analysis, which will disable some optimisations.
In the following benchmark, we create a copy and return only one field from the new Object32 created.
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public int testCopy() {
return new Object32(original).f29;
}
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public int testClone() {
return original.clone().f29;
}
And the results are that even though clone is more efficient for a 32 fields object
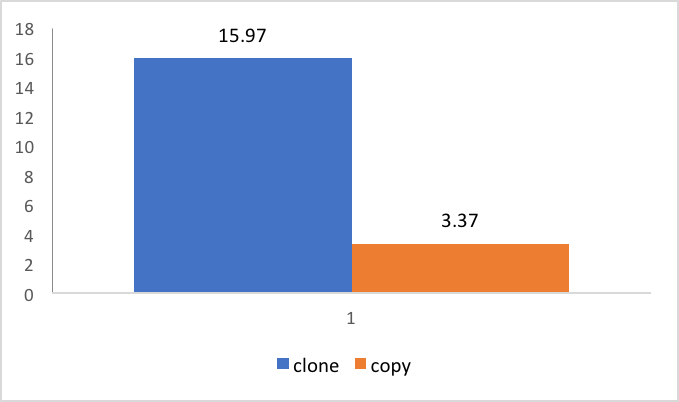
the clone benchmark is more than 4 times slower! What happened?
Let’s have a closer look at the asm to see under the hood.
asm clone
In the asm for testClone is similar to the one for Object4CopyVsCloneBenchmark.testClone.
On Line 26 it allocates 144 bytes - 90 in hexadecimal -, that’s 12 bytes for header + 32 * 4 = 128 bytes for the fields and 4 bytes lost for alignment.
0x000000010ceebe8c: mov 0xc(%rsi),%r9d ;*getfield original
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testClone@1 (line 69)
0x000000010ceebe90: test %r9d,%r9d
0x000000010ceebe93: je L0002 ;*invokespecial clone
; - com.github.arnaudroger.beans.Object32::clone@1 (line 111)
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testClone@4 (line 69)
0x000000010ceebe99: lea (%r12,%r9,8),%rbp ;*getfield original
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testClone@1 (line 69)
0x000000010ceebe9d: mov 0x60(%r15),%rbx
0x000000010ceebea1: mov %rbx,%r10
0x000000010ceebea4: add $0x90,%r10 ;** object length
0x000000010ceebeab: cmp 0x70(%r15),%r10
0x000000010ceebeaf: jae L0001
0x000000010ceebeb1: mov %r10,0x60(%r15)
0x000000010ceebeb5: prefetchnta 0xc0(%r10)
0x000000010ceebebd: mov $0xf8015eab,%r11d ; {metadata('com/github/arnaudroger/beans/Object32')}
0x000000010ceebec3: movabs $0x0,%r10
0x000000010ceebecd: lea (%r10,%r11,8),%r10
0x000000010ceebed1: mov 0xa8(%r10),%r10
0x000000010ceebed8: mov %r10,(%rbx)
0x000000010ceebedb: movl $0xf8015eab,0x8(%rbx) ; {metadata('com/github/arnaudroger/beans/Object32')}
L0000: lea 0x8(%r12,%r9,8),%rdi ;** src
0x000000010ceebee7: mov %rbx,%rsi ;** dest
0x000000010ceebeea: add $0x8,%rsi ;** add offset of 8
0x000000010ceebeee: mov $0x11,%edx ;** length to copy 0x11 * 8 = 136 bytes
0x000000010ceebef3: movabs $0x10cd5d780,%r10
0x000000010ceebefd: callq *%r10 ;*invokespecial clone
; - com.github.arnaudroger.beans.Object32::clone@1 (line 111)
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testClone@4 (line 69)
0x000000010ceebf00: mov 0x7c(%rbx),%eax ;*getfield f29 ** 7c is 124 bytes, minus the headers 112 that offset 28 ints
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testClone@7 (line 69)
0x000000010ceebf03: add $0x20,%rsp
0x000000010ceebf07: pop %rbp
0x000000010ceebf08: test %eax,-0xb154f0e(%rip) # 0x0000000101d97000
; {poll_return} *** SAFEPOINT POLL ***
0x000000010ceebf0e: retq
asm copy
In the copy one, it does not even copy the object but just returns the f29 field from the original object. Because the copy did not escape, and the copy creation did not have any side effects, it is safe to totally remove the creation of the new object.
0x0000000109c7b1cc: mov 0xc(%rsi),%r11d ;*getfield original
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testCopy@5 (line 63)
0x0000000109c7b1d0: mov 0x7c(%r12,%r11,8),%eax ;*getfield f29 ** 7c is 124 bytes, minus the headers 112 that offset 28 ints
; - com.github.arnaudroger.beans.Object32::<init>@230 (line 67)
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testCopy@8 (line 63)
; implicit exception: dispatches to 0x0000000109c7b1e1
0x0000000109c7b1d5: add $0x10,%rsp
0x0000000109c7b1d9: pop %rbp
0x0000000109c7b1da: test %eax,-0x47b81e0(%rip) # 0x00000001054c3000
; {poll_return} *** SAFEPOINT POLL ***
0x0000000109c7b1e0: retq
Summary
The clone method will perform better on on big objects but be sure that your code will not benefit from escape analysis.
In any case, it might not make a big difference to your overall code, so Doug Lea’s advice is still partially valid, avoid unless for array copy but Arrays.copyOf is as good there, so really you can totally stay away from void.array copy and