ArrayList.get(i) vs array[i]
I recently did a presentation at the Belfast JUG about some work I did try to optimise the Re2j library.
One of the first changes I made was replacing 2 ArrayList by 2 Arrays. That lead to a 10% perf improvement in my benchmark which was quite big for such a simple change, I assumed that it was mainly due to the size check removal but it was not the full story.
In this blog post, I will try to dig deeper as to where the performance improvement actually came from.
We will first have a look at random access and then sequential access. For both access patterns, I started with an accidentally flawed benchmark, which we will go through for education purpose. The final result - unless some other issue is discovered later - is in the TL;DR, if you are not interested in how easy it is to mess up a benchmark.
TL;DR
Random ArrayList access is about 6% more expensive because of the size check and cast check introduced in the ArrayList.
Random access average invocation time
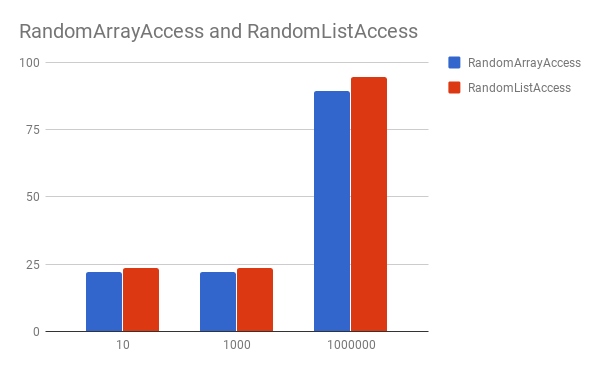
For sequential access it seems Array can be a lot faster especially for smaller ones.
On the long add loop, there is 50% perf difference for 10 elements, 80% on a 1000 elements, but that number may only apply to an add loop, allowing for more optimisations.
It’s hard to tell if those numbers can be generalised to other kinds of work than numerical one.
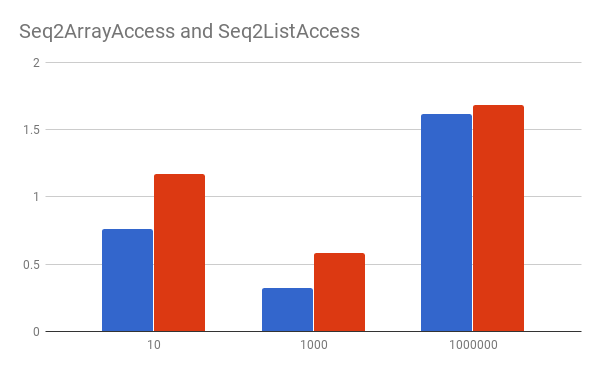
Sequential access average time of 1 get
A word about ArrayList<E>
ArrayList<E> provide a List implementation backed by an Object[].
Why not an use E[]? Because of erasure, the actual type E of the ArrayList is lost at runtime.
The code to do a ArrayList.get(index) is then equivalent to
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
return (E) elementData[index];
Random Access
In this section, we will look at the random access pattern, where we will do a read at random index on each invocation.
The data is just a Long[] or ArrayList
RandomAccess Benchmark Try 1
RandomArrayAccess
@Setup(Level.Invocation)
public void nextIndex() {
index = random.nextInt(size);
}
@Benchmark
public Long testGet() {
return data[index];
}
RandomListAccess
@Setup(Level.Invocation)
public void nextIndex() {
index = random.nextInt(size);
}
@Benchmark
public Long testGet() {
return data.get(index);
}
RandomAccess results
java -jar target/benchmark.jar -bm avgt -tu ns
In the following result, you can see a 10% penalty for using ArrayList,
and a massive 160% difference for a 1 million elements array, which is pretty suspicious.
Benchmark (size) Mode Cnt Score Error Units
RandomArrayAccess.testGet 10 avgt 200 20.983 ± 0.229 ns/op
RandomListAccess.testGet 10 avgt 200 23.161 ± 0.097 ns/op
RandomArrayAccess.testGet 1000 avgt 200 20.600 ± 0.074 ns/op
RandomListAccess.testGet 1000 avgt 200 23.457 ± 0.133 ns/op
RandomArrayAccess.testGet 1000000 avgt 200 33.545 ± 0.035 ns/op
RandomListAccess.testGet 1000000 avgt 200 90.301 ± 0.246 ns/op
RandomArrayAccess asm
java -jar target/benchmark.jar -bm avgt -tu ns -f 1 -prof perfasm Random
The asm for array access is pretty simple.
- load the index
0.40% 0x00007f85e12274c3: mov %rax,0x10(%rsp) ; 0x00007f85e12274c8: mov 0x70(%rsp),%r10 0x00007f85e12274cd: mov 0x10(%r10),%r10d ;*getfield index ; - com.github.arnaudroger.RandomArrayAccess::testGet@5 (line 69) ; - com.github.arnaudroger.generated.RandomArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439) - load the array address
0.76% 0.05% 0x00007f85e12274d1: mov 0x70(%rsp),%r11 ; 0x00007f85e12274d6: mov 0x14(%r11),%r8d ;*getfield data ; - com.github.arnaudroger.RandomArrayAccess::testGet@1 (line 69) ; - com.github.arnaudroger.generated.RandomArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439) - implicit boundary check
0.32% 0.53% 0x00007f85e12274da: mov 0xc(%r12,%r8,8),%r9d ; implicit exception: dispatches to 0x00007f85e1227895 1.94% 6.06% 0x00007f85e12274df: cmp %r9d,%r10d 0x00007f85e12274e2: jae 0x00007f85e1227605 - load the element
0.68% 2.19% 0x00007f85e12274e8: lea (%r12,%r8,8),%r11 ; 0x00007f85e12274ec: mov 0x10(%r11,%r10,4),%r10d 0x00007f85e12274f1: mov %r10,%rdx 0x00007f85e12274f4: shl $0x3,%rdx ;*aaload ; - com.github.arnaudroger.RandomArrayAccess::testGet@8 (line 69) ; - com.github.arnaudroger.generated.RandomArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439)
RandomListAccess asm
The ArrayList has a lot more going on
- load the index
0.18% │ 0x00007fa82d25427b: mov %rax,0x10(%rsp) ; │ 0x00007fa82d254280: mov 0x70(%rsp),%r10 │ 0x00007fa82d254285: mov 0x10(%r10),%r8d ;*getfield index │ ; - com.github.arnaudroger.RandomListAccess::testGet@5 (line 85) │ ; - com.github.arnaudroger.generated.RandomListAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439) - load the ArrayList address
0.42% 0.70% │ 0x00007fa82d254289: mov 0x14(%r10),%r10d ;*getfield data │ ; - com.github.arnaudroger.RandomListAccess::testGet@1 (line 85) │ ; - com.github.arnaudroger.generated.RandomListAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439) - load the size
│ 0x00007fa82d25428d: mov 0x10(%r12,%r10,8),%r11d ;*getfield size │ ; - java.util.ArrayList::rangeCheck@2 (line 652) │ ; - java.util.ArrayList::get@2 (line 429) │ ; - com.github.arnaudroger.RandomListAccess::testGet@8 (line 85) │ ; - com.github.arnaudroger.generated.RandomListAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439) │ ; implicit exception: dispatches to 0x00007fa82d254785 - do the range check index < size
0.96% 3.38% │ 0x00007fa82d254292: cmp %r11d,%r8d ; │ 0x00007fa82d254295: jge 0x00007fa82d254625 ;*if_icmplt │ ; - java.util.ArrayList::rangeCheck@5 (line 652) │ ; - java.util.ArrayList::get@2 (line 429) │ ; - com.github.arnaudroger.RandomListAccess::testGet@8 (line 85) │ ; - com.github.arnaudroger.generated.RandomListAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439) - load the underlying elementData array address
0.42% 0.88% │ 0x00007fa82d25429b: mov 0x14(%r12,%r10,8),%r11d ;*getfield elementData │ ; - java.util.ArrayList::elementData@1 (line 418) │ ; - java.util.ArrayList::get@7 (line 431) │ ; - com.github.arnaudroger.RandomListAccess::testGet@8 (line 85) │ ; - com.github.arnaudroger.generated.RandomListAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439) - implicit boundary check
│ 0x00007fa82d2542a0: mov 0xc(%r12,%r11,8),%r10d ; implicit exception: dispatches to 0x00007fa82d2547a9 0.99% 2.44% │ 0x00007fa82d2542a5: cmp %r10d,%r8d │ 0x00007fa82d2542a8: jae 0x00007fa82d254459 - and 8 load the element and checkcast
│ 0x00007fa82d2542b2: mov 0x10(%r10,%r8,4),%r10d ;*aaload │ ; - java.util.ArrayList::elementData@5 (line 418) │ ; - java.util.ArrayList::get@7 (line 431) │ ; - com.github.arnaudroger.RandomListAccess::testGet@8 (line 85) │ ; - com.github.arnaudroger.generated.RandomListAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439) │ 0x00007fa82d2542b7: mov 0x8(%r12,%r10,8),%r8d ; implicit exception: dispatches to 0x00007fa82d2547cd 0.92% 1.64% │ 0x00007fa82d2542bc: cmp $0xf80022ae,%r8d ; {metadata('java/lang/Long')} │ 0x00007fa82d2542c3: jne 0x00007fa82d2546f5 0.16% 0.01% │ 0x00007fa82d2542c9: lea (%r12,%r10,8),%rdx ;*checkcast │ ; - com.github.arnaudroger.RandomListAccess::testGet@11 (line 85) │ ; - com.github.arnaudroger.generated.RandomListAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439)
Note that the checkcast and the element load are interleaved together in the asm. the lea - load effective address - instruction is wrongly annotated as the checkcast here when it is the actual array access.
that can explain the 10% difference between ArrayList.get(i) and Array[i].
What explains the 160% difference though on the 1000000 size?
if you look at the perf asm result for the 1000000 size.
0.31% 1.22% │ │ 0x00007f0a152457e9: lea (%r12,%r11,8),%r10
│ │ 0x00007f0a152457ed: mov 0x10(%r10,%r8,4),%r10d ;*aaload
│ │ ; - java.util.ArrayList::elementData@5 (line 418)
│ │ ; - java.util.ArrayList::get@7 (line 431)
│ │ ; - com.github.arnaudroger.RandomListAccess::testGet@8 (line 85)
│ │ ; - com.github.arnaudroger.generated.RandomListAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439)
10.89% 5.39% │ │ 0x00007f0a152457f2: mov 0x8(%r12,%r10,8),%r8d ; implicit exception: dispatches to 0x00007f0a15245e19
34.86% 0.32% │ │ 0x00007f0a152457f7: cmp $0xf80022ae,%r8d ; {metadata('java/lang/Long')}
│ │ 0x00007f0a152457fe: jne 0x00007f0a15245d41
0.21% │ │ 0x00007f0a15245804: lea (%r12,%r10,8),%rdx ;*checkcast
│ │ ; - com.github.arnaudroger.RandomListAccess::testGet@11 (line 85)
│ │ ; - com.github.arnaudroger.generated.RandomListAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439)
It spent 34% of the cycles on checkcast!
Now if we look at the perfnorm profile :
Benchmark (size) Mode Cnt Score Error Units
RandomArrayAccess.testGet:CPI 1000000 thrpt 0.982 #/op
RandomListAccess.testGet:CPI 1000000 thrpt 1.606 #/op
RandomArrayAccess.testGet:L1-dcache-load-misses 1000000 thrpt 1.004 #/op
RandomListAccess.testGet:L1-dcache-load-misses 1000000 thrpt 3.098 #/op
RandomArrayAccess.testGet:LLC-loads 1000000 thrpt 0.944 #/op
RandomListAccess.testGet:LLC-loads 1000000 thrpt 2.138 #/op
RandomArrayAccess.testGet:branches 1000000 thrpt 56.780 #/op
RandomListAccess.testGet:branches 1000000 thrpt 59.068 #/op
RandomArrayAccess.testGet:cycles 1000000 thrpt 324.400 #/op
RandomListAccess.testGet:cycles 1000000 thrpt 541.267 #/op
RandomArrayAccess.testGet:instructions 1000000 thrpt 330.514 #/op
RandomListAccess.testGet:instructions 1000000 thrpt 336.976 #/op
The biggest difference is the number of L1 cache misses, 3 times as many. In the Array case because we don’t do anything with the Long, we will cache miss only on the lea instruction.
But in the ArrayList we need to do a checkcast, to do that we need to read the memory where the Long resides increasing the chances of a cache miss.
In a real application we are likely to do something with the element of the Array, it is therefore not a fair benchmark. That issue is also likely to impact the smaller size Array.
RandomAccess Benchmark - Try 2
We can force a read of the value easily by returning a long instead of Long triggering an unboxing call of longValue().
Random2ArrayAccess
@Benchmark
public long testGet() {
return data[index];
}
Random2ListAccess
@Benchmark
public long testGet() {
return data.get(index);
}
avgt
As you can see in the following table and graph, the result looks more consistent with 7-6% performance penalty on the ArrayList.
Benchmark (size) Mode Cnt Score Error Units
Random2ArrayAccess.testGet 10 avgt 200 21.938 ± 0.032 ns/op
Random2ListAccess.testGet 10 avgt 200 23.489 ± 0.039 ns/op
Random2ArrayAccess.testGet 1000 avgt 200 22.252 ± 0.030 ns/op
Random2ListAccess.testGet 1000 avgt 200 23.764 ± 0.050 ns/op
Random2ArrayAccess.testGet 1000000 avgt 200 89.436 ± 0.224 ns/op
Random2ListAccess.testGet 1000000 avgt 200 94.676 ± 0.240 ns/op
Random2 Asm
I will skip on the full asm for that one. It is very similar to Try 1 with an additional longValue call.
0.43% 0.19% │ 0x00007f0eb5243aaf: mov 0x10(%r12,%r10,8),%rdx ;*getfield value
│ ; - java.lang.Long::longValue@1 (line 1000)
│ ; - com.github.arnaudroger.Random2ArrayAccess::testGet@9 (line 67)
│ ; - com.github.arnaudroger.generated.Random2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@149 (line 439)
│ ; implicit exception: dispatches to 0x00007f0eb5243f45
Sequential Access
Let’s now have a look at sequential access.
Sequential Benchmark Try 1
we will just iterate over the Array/ArrayList and pass the value to the Blackhole to protect against dead code elimination.
SeqArrayAccess
@Benchmark
public void testGet(Blackhole b) {
for(Long l : data) {
b.consume(l);
}
}
SeqListAccess
@Benchmark
public void testNewForEach(Blackhole b) {
data.forEach(b::consume);
}
@Benchmark
public void testClassicForEach(Blackhole b) {
for(Long l : data) {
b.consume(l);
}
}
@Benchmark
public void testIndexed(Blackhole b) {
ArrayList<Long> data = this.data;
int size = data.size();
for(int i = 0; i < size; i++) {
b.consume(data.get(i));
}
}
Avgt
In the sequential access the number are consistent across size, with at least 45% penalty across the board. ArrayList indexed access is faster, then for each loop, then ArrayList.forEach - that would in itself deserve some more analysis, but for now I will focus on the indexed access. But beware we will need to check that does not number are actually representative of a real use case - and as we will see it it not.
SeqArrayAccess.testGet 1000000 avgt 200 2633544.985 ± 2389.151 ns/op
SeqListAccess.testIndexed 1000000 avgt 200 3720347.588 ± 7958.779 ns/op
SeqListAccess.testClassicForEach 1000000 avgt 200 4251067.025 ± 11038.199 ns/op
SeqListAccess.testNewForEach 1000000 avgt 200 4435148.392 ± 41712.575 ns/op
x86 asm
SeqArray
What can we see in the asm for the Array is pretty simple.
- load data from (%rsp)
9.90% 10.66% ││↗ 0x00007f269d22f4c1: mov (%rsp),%r10 ;*aload_2 │││ ; - com.github.arnaudroger.SeqArrayAccess::testGet@17 (line 61) │↘│ 0x00007f269d22f4c5: mov 0x10(%r10,%rbp,4),%r11d 0.70% 0.54% │ │ 0x00007f269d22f4ca: mov %r10,(%rsp) 0.04% 0.03% │ │ 0x00007f269d22f4ce: mov %r11,%rdx - load element - no boundary check
9.47% 8.56% │ │ 0x00007f269d22f4d1: shl $0x3,%rdx ;*aaload │ │ ; - com.github.arnaudroger.SeqArrayAccess::testGet@20 (line 61) 0.18% 0.06% │ │ 0x00007f269d22f4d5: mov 0x8(%rsp),%rsi - call consume
0.01% 0.04% │ │ 0x00007f269d22f4da: nop 0.05% 0.03% │ │ 0x00007f269d22f4db: callq 0x00007f269d046020 ; OopMap{[0]=Oop [8]=Oop off=128} │ │ ;*invokevirtual consume │ │ ; - com.github.arnaudroger.SeqArrayAccess::testGet@26 (line 62) │ │ ; {optimized virtual_call} - increment counter - ebp
10.35% 13.07% │ │ 0x00007f269d22f4e0: inc %ebp ;*iinc │ │ ; - com.github.arnaudroger.SeqArrayAccess::testGet@29 (line 61) - check counter against size - 0x10(%rsp), loop
0.03% 0.03% │ │ 0x00007f269d22f4e2: cmp 0x10(%rsp),%ebp │ ╰ 0x00007f269d22f4e6: jl 0x00007f269d22f4c1 ;*if_icmpge │ ; - com.github.arnaudroger.SeqArrayAccess::testGet@14 (line 61)SeqListAccessIndexed
for the ArrayList indexed access there is a bit more happening.
- load data
0x00007f2925225ec7: lea (%r12,%r11,8),%rcx ;*getfield data ; - com.github.arnaudroger.SeqListAccess::testIndexed@1 (line 74) - load data.size
6.59% 4.76% │ ↗ 0x00007f2925225ed2: mov 0x8(%rsp),%r11d │ │ 0x00007f2925225ed7: mov 0x10(%r12,%r11,8),%r10d ;*getfield size │ │ ; - java.util.ArrayList::rangeCheck@2 (line 652) │ │ ; - java.util.ArrayList::get@2 (line 429) │ │ ; - com.github.arnaudroger.SeqListAccess::testIndexed@23 (line 77) - range check test
↘ │ 0x00007f2925225eea: cmp %r10d,%ebp │ 0x00007f2925225eed: jge 0x00007f2925225f65 ;*if_icmplt │ ; - java.util.ArrayList::rangeCheck@5 (line 652) │ ; - java.util.ArrayList::get@2 (line 429) │ ; - com.github.arnaudroger.SeqListAccess::testIndexed@23 (line 77) - load data.elementData
0.15% 0.08% │ 0x00007f2925225eef: mov 0x14(%r12,%r11,8),%r10d ;*getfield elementData │ ; - java.util.ArrayList::elementData@1 (line 418) │ ; - java.util.ArrayList::get@7 (line 431) │ ; - com.github.arnaudroger.SeqListAccess::testIndexed@23 (line 77) - implicit boundary check - why not eliminated?
1.40% 1.46% │ 0x00007f2925225ef4: mov 0xc(%r12,%r10,8),%r8d ; implicit exception: dispatches to 0x00007f2925225fb6 9.69% 10.38% │ 0x00007f2925225ef9: cmp %r8d,%ebp ╭│ 0x00007f2925225efc: jae 0x00007f2925225f40 - load element - no check cast here as consume take an Object so not needed
3.95% 4.98% ││ 0x00007f2925225efe: mov %rcx,0x10(%rsp) 0.04% 0.03% ││ 0x00007f2925225f03: mov %r9d,0xc(%rsp) 0.49% 0.50% ││ 0x00007f2925225f08: mov %r11d,0x8(%rsp) 2.68% 2.58% ││ 0x00007f2925225f0d: mov %rdx,(%rsp) 3.80% 3.86% ││ 0x00007f2925225f11: shl $0x3,%r10 0.04% 0.07% ││ 0x00007f2925225f15: mov 0x10(%r10,%rbp,4),%r11d 4.53% 3.99% ││ 0x00007f2925225f1a: mov %r11,%rdx 2.14% 2.49% ││ 0x00007f2925225f1d: shl $0x3,%rdx ;*aaload ││ ; - java.util.ArrayList::elementData@5 (line 418) ││ ; - java.util.ArrayList::get@7 (line 431) ││ ; - com.github.arnaudroger.SeqListAccess::testIndexed@23 (line 77) - call consumer
4.24% 4.03% ││ 0x00007f2925225f21: mov (%rsp),%rsi 0.11% 0.06% ││ 0x00007f2925225f25: xchg %ax,%ax 0.49% 0.37% ││ 0x00007f2925225f27: callq 0x00007f2925046020 ; OopMap{[0]=Oop [8]=NarrowOop [16]=Oop off=172} ││ ;*invokevirtual consume ││ ; - com.github.arnaudroger.SeqListAccess::testIndexed@26 (line 77) ││ ; {optimized virtual_call} - inc counter and check against size - 0x10(%rsp), loop to 2
6.70% 5.13% ││ 0x00007f2925225f2c: inc %ebp ;*iinc ││ ; - com.github.arnaudroger.SeqListAccess::testIndexed@29 (line 76) 0.11% 0.08% ││ 0x00007f2925225f2e: cmp 0xc(%rsp),%ebp │╰ 0x00007f2925225f32: jl 0x00007f2925225ed2 ;*if_icmpge │ ; - com.github.arnaudroger.SeqListAccess::testIndexed@16 (line 76)
So the cast has been removed - as the Blackhole takes an Object -, which is unlikely to happen in real world app.
but the boundary check elimination did not happen because consume is blocking that optimisation.
That benchmark is probably not good for what we want to analyse there….
Sequential - Try 2
Will avoid using the Blackhole in the loop by just calculating the sum of the elements and returning it.
Seq2ArrayAccess
@Benchmark
public long testGet() {
long total = 0;
for(Long l : data) {
total += l;
}
return total;
}
Seq2ListAccess
@Benchmark
public long testIndexed() {
ArrayList<Long> data = this.data;
int size = data.size();
long total = 0;
for(int i = 0; i < size; i++) {
total += data.get(i);
}
return total;
}
avgt
Benchmark (size) Mode Cnt Score Error Units
Seq2ArrayAccess.testGet 10 avgt 200 7.653 ± 0.017 ns/op
Seq2ListAccess.testIndexed 10 avgt 200 11.702 ± 0.120 ns/op
Seq2ArrayAccess.testGet 1000 avgt 200 320.084 ± 0.616 ns/op
Seq2ListAccess.testIndexed 1000 avgt 200 585.754 ± 0.471 ns/op
Seq2ArrayAccess.testGet 1000000 avgt 200 1620174.088 ± 2663.118 ns/op
Seq2ListAccess.testIndexed 1000000 avgt 200 1681210.020 ± 3470.300 ns/op
here we can still see a big penalty - 50%, 80%, 3% - on the ArrayList with a big convergence of perf for bigger arrays.
x86 asm
The asm is quite interesting on the size of 10.
Seq2Array asm
there is a lot more asm generated. You can see that the loop is first unrolled and then loop one by one :
↗│ 0x00007f368439fe58: mov 0x10(%rsi,%rdi,4),%r10d ;*aaload
││ ; - com.github.arnaudroger.Seq2ArrayAccess::testGet@24 (line 57)
││ ; - com.github.arnaudroger.generated.Seq2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@17 (line 232)
3.33% 2.72% ││ 0x00007f368439fe5d: add 0x10(%r12,%r10,8),%rdx ;*ladd
││ ; - com.github.arnaudroger.Seq2ArrayAccess::testGet@33 (line 58)
││ ; - com.github.arnaudroger.generated.Seq2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@17 (line 232)
││ ; implicit exception: dispatches to 0x00007f368439ff13
0.17% 0.15% ││ 0x00007f368439fe62: inc %edi ;*iinc
││ ; - com.github.arnaudroger.Seq2ArrayAccess::testGet@35 (line 57)
││ ; - com.github.arnaudroger.generated.Seq2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@17 (line 232)
0.00% ││ 0x00007f368439fe64: cmp %r9d,%edi
╰│ 0x00007f368439fe67: jl 0x00007f368439fe58 ;*if_icmpge
the unrolled part is loading the value in a different registers - rdx, rax, r8, and r11.
3.09% 4.08% │ │ 0x00007f368439fde2: mov 0x10(%r12,%r8,8),%r10d ;*aaload
│ │ ; - com.github.arnaudroger.Seq2ArrayAccess::testGet@24 (line 57)
│ │ ; - com.github.arnaudroger.generated.Seq2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@17 (line 232)
0.01% 0.00% │ │ 0x00007f368439fde7: mov 0x10(%r12,%r10,8),%rdx ;*getfield value
│ │ ; - java.lang.Long::longValue@1 (line 1000)
│ │ ; - com.github.arnaudroger.Seq2ArrayAccess::testGet@30 (line 58)
│ │ ; - com.github.arnaudroger.generated.Seq2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@17 (line 232)
│ │ ; implicit exception: dispatches to 0x00007f368439ff13
0.11% 0.07% ││ │ 0x00007f368439fe20: mov 0x14(%rsi,%rcx,4),%r11d ;*aaload
││ │ ; - com.github.arnaudroger.Seq2ArrayAccess::testGet@24 (line 57)
││ │ ; - com.github.arnaudroger.generated.Seq2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@17 (line 232)
0.00% 0.01% ││ │ 0x00007f368439fe25: mov 0x10(%r12,%r11,8),%rax ;*getfield value
││ │ ; - java.lang.Long::longValue@1 (line 1000)
││ │ ; - com.github.arnaudroger.Seq2ArrayAccess::testGet@30 (line 58)
││ │ ; - com.github.arnaudroger.generated.Seq2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@17 (line 232)
││ │ ; implicit exception: dispatches to 0x00007f368439ff13
2.11% 2.34% ││ │ 0x00007f368439fe2a: mov 0x18(%rsi,%rcx,4),%r8d ;*aaload
││ │ ; - com.github.arnaudroger.Seq2ArrayAccess::testGet@24 (line 57)
││ │ ; - com.github.arnaudroger.generated.Seq2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@17 (line 232)
5.45% 4.88% ││ │ 0x00007f368439fe2f: mov 0x10(%r12,%r8,8),%r8 ;*getfield value
││ │ ; - java.lang.Long::longValue@1 (line 1000)
││ │ ; - com.github.arnaudroger.Seq2ArrayAccess::testGet@30 (line 58)
││ │ ; - com.github.arnaudroger.generated.Seq2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@17 (line 232)
││ │ ; implicit exception: dispatches to 0x00007f368439ff13
1.33% 1.37% ││ │ 0x00007f368439fe34: mov 0x1c(%rsi,%rcx,4),%r11d ;*aaload
││ │ ; - com.github.arnaudroger.Seq2ArrayAccess::testGet@24 (line 57)
││ │ ; - com.github.arnaudroger.generated.Seq2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@17 (line 232)
││ │ 0x00007f368439fe39: mov 0x10(%r12,%r11,8),%r11 ;*getfield value
││ │ ; - java.lang.Long::longValue@1 (line 1000)
││ │ ; - com.github.arnaudroger.Seq2ArrayAccess::testGet@30 (line 58)
││ │ ; - com.github.arnaudroger.generated.Seq2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@17 (line 232)
││ │ ; implicit exception: dispatches to 0x00007f368439ff13
and then does all the adds in one go.
2.03% 2.06% ││ │ 0x00007f368439fe3e: add %rax,%rdx
5.28% 4.58% ││ │ 0x00007f368439fe41: add %r8,%rdx
3.06% 2.91% ││ │ 0x00007f368439fe44: add %r11,%rdx ;*ladd
││ │ ; - com.github.arnaudroger.Seq2ArrayAccess::testGet@33 (line 58)
││ │ ; - com.github.arnaudroger.generated.Seq2ArrayAccess_testGet_jmhTest::testGet_avgt_jmhStub@17 (line 232)
Seq2List asm
the List loop is also unrolled,
but the longValue() and add
are done sequentially
on the same register rdx.
7.88% 7.01% │ │ │ 0x00007f8e687c5924: lea (%r12,%rdi,8),%rax ;*aaload
│ │ │ ; - java.util.ArrayList::elementData@5 (line 418)
│ │ │ ; - java.util.ArrayList::get@7 (line 431)
│ │ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@25 (line 63)
│ │ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
0.00% 0.00% │ │ │ 0x00007f8e687c5928: cmp $0xf80022ae,%ebx ; {metadata('java/lang/Long')}
│ │ │ 0x00007f8e687c592e: jne 0x00007f8e687c5c3f ;*checkcast
│ │ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@28 (line 63)
│ │ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
2.19% 1.86% │ │ │ 0x00007f8e687c5934: add 0x10(%rax),%rdx ;*ladd
│ │ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@34 (line 63)
│ │ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
....
2.05% 1.25% │ ││ │ 0x00007f8e687c596a: lea (%r12,%rbx,8),%rax ;*aaload
│ ││ │ ; - java.util.ArrayList::elementData@5 (line 418)
│ ││ │ ; - java.util.ArrayList::get@7 (line 431)
│ ││ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@25 (line 63)
│ ││ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
0.58% 0.63% │ ││ │ 0x00007f8e687c596e: cmp $0xf80022ae,%r10d ; {metadata('java/lang/Long')}
│ ││ │ 0x00007f8e687c5975: jne 0x00007f8e687c5c3f ;*checkcast
│ ││ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@28 (line 63)
│ ││ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
1.65% 1.61% │ ││ │ 0x00007f8e687c597b: add 0x10(%rax),%rdx ;*ladd
│ ││ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@34 (line 63)
│ ││ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
...
1.49% 1.05% ││ ││ │ 0x00007f8e687c5995: lea (%r12,%r10,8),%rax ;*aaload
││ ││ │ ; - java.util.ArrayList::elementData@5 (line 418)
││ ││ │ ; - java.util.ArrayList::get@7 (line 431)
││ ││ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@25 (line 63)
││ ││ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
1.64% 0.94% ││ ││ │ 0x00007f8e687c5999: cmp $0xf80022ae,%esi ; {metadata('java/lang/Long')}
││ ││ │ 0x00007f8e687c599f: jne 0x00007f8e687c5c3c ;*checkcast
││ ││ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@28 (line 63)
││ ││ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
0.78% 0.74% ││ ││ │ 0x00007f8e687c59a9: add 0x10(%rax),%rdx ;*ladd
...
││ ││ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@34 (line 63)
││ ││ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
0.97% 0.38% │││ ││ │ 0x00007f8e687c59ba: lea (%r12,%rsi,8),%rax ;*aaload
│││ ││ │ ; - java.util.ArrayList::elementData@5 (line 418)
│││ ││ │ ; - java.util.ArrayList::get@7 (line 431)
│││ ││ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@25 (line 63)
│││ ││ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
0.45% 0.29% │││ ││ │ 0x00007f8e687c59be: cmp $0xf80022ae,%r10d ; {metadata('java/lang/Long')}
│││ ││ │ 0x00007f8e687c59c5: jne 0x00007f8e687c5c36 ;*checkcast
│││ ││ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@28 (line 63)
│││ ││ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
1.56% 0.09% │││ ││ │ 0x00007f8e687c59cf: add 0x10(%rax),%rdx ;*ladd
│││ ││ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@34 (line 63)
│││ ││ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
...
0.98% 0.50% ││││││ │ 0x00007f8e687c59dc: lea (%r12,%rbx,8),%rax ;*aaload
││││││ │ ; - java.util.ArrayList::elementData@5 (line 418)
││││││ │ ; - java.util.ArrayList::get@7 (line 431)
││││││ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@25 (line 63)
││││││ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
1.61% 0.20% ││││││ │ 0x00007f8e687c59e0: cmp $0xf80022ae,%r10d ; {metadata('java/lang/Long')}
││││││ │ 0x00007f8e687c59e7: jne 0x00007f8e687c5c30 ;*checkcast
││││││ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@28 (line 63)
││││││ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
1.38% 0.59% ││││││ │ 0x00007f8e687c59ed: add 0x10(%rax),%rdx ;*ladd
││││││ │ ; - com.github.arnaudroger.Seq2ListAccess::testIndexed@34 (line 63)
││││││ │ ; - com.github.arnaudroger.generated.Seq2ListAccess_testIndexed_jmhTest::testIndexed_avgt_jmhStub@17 (line 232)
The checkcasts are still there, but no more implicit boundary check.
Which is closer to what you expect in a real application.
Iterating over the ArrayList introduce a lot more instruction due to the checkcast reducing the opportunity to keep the cpu busy.
But then why are the perf equivalent on the 1000000 sized array?
perfnorm
java -jar target/benchmark.jar -f 1 -prof perfnorm
I extracted the Clock Per Instruction - the lower the better -, L1 cache misses - the lower the better -, and number of instructions for the perfnorm run in the following table.
Seq2ArrayAccess.testGet:CPI 10 avgt 0.343 #/op
Seq2ArrayAccess.testGet:L1-dcache-load-misses 10 avgt ≈ 10⁻⁴ #/op
Seq2ArrayAccess.testGet:instructions 10 avgt 84.044 #/op
Seq2ListAccess.testIndexed:instructions 10 avgt 146.788 #/op
Seq2ListAccess.testIndexed:CPI 10 avgt 0.295 #/op
Seq2ListAccess.testIndexed:L1-dcache-load-misses 10 avgt 0.002 #/op
Seq2ArrayAccess.testGet:CPI 1000 avgt 0.317 #/op
Seq2ArrayAccess.testGet:L1-dcache-load-misses 1000 avgt 8.089 #/op
Seq2ArrayAccess.testGet:instructions 1000 avgt 3794.591 #/op
Seq2ListAccess.testIndexed:CPI 1000 avgt 0.259 #/op
Seq2ListAccess.testIndexed:L1-dcache-load-misses 1000 avgt 9.929 #/op
Seq2ListAccess.testIndexed:instructions 1000 avgt 8562.880 #/op
Seq2ArrayAccess.testGet:instructions 1000000 avgt 3747496.801 #/op
Seq2ArrayAccess.testGet:CPI 1000000 avgt 1.634 #/op
Seq2ArrayAccess.testGet:L1-dcache-load-misses 1000000 avgt 441021.756 #/op
Seq2ListAccess.testIndexed:instructions 1000000 avgt 8514529.296 #/op
Seq2ListAccess.testIndexed:CPI 1000000 avgt 0.741 #/op
Seq2ListAccess.testIndexed:L1-dcache-load-misses 1000000 avgt 439508.067 #/op
With 10 and 1000 elements the number of cache misses is pretty low, the number of instruction and the CPI are lower for Array - no wonder it’s faster less to do, and less cycle to do it -. But on the 1000000 size array there are loads of cache misses. They end-up dominating the performance, increasing the CPI to 1.6 for the Array. The only reason the ArrayList does not score as bad is because it has a lot more instructions.