Java Performance Puzzle Part2
This post is a follow-up to Java Performance Puzzle in which a small code change leads to a counter-intuitive performance gain.
Simplified case
In the previous post, the benchmark was based on the code from my CSV parser with all the logic to deal with unescaping, the cell aggregation etc …
simplified for-loop
I managed to reduce the code to a simpler naive CSV parser. see SimplifiedBenchmark.java
We now have a tight loop with 2 conditions in which with extract the char[], accumulate it in an array and pass the array
to the Blackhole when encountering '\n'.
@Benchmark
public void benchmarkDirect(CsvContent csvContent, Blackhole blackhole) {
// snip ...
for(int currentIndex = 0; currentIndex < content.length; currentIndex++) {
char c = content[currentIndex];
if (c == ',') {
cells[cellIndex++] = Arrays.copyOfRange(content, startCell, currentIndex);
startCell = currentIndex + 1;
} else if (c == '\n') {
cells[cellIndex++] = Arrays.copyOfRange(content, startCell, currentIndex);
startCell = currentIndex + 1;
blackhole.consume(cells);
cellIndex = 0;
}
}
}
@Benchmark
public void benchmarkHolder(CsvContent csvContent, Blackhole blackhole) {
// snip ...
for(int currentIndex = 0; currentIndex < content.length; currentIndex++) {
char c = content[currentIndex];
if (c == ',') {
int startCell = holder.startCell;
cells[cellIndex++] = Arrays.copyOfRange(content, startCell, currentIndex);
holder.startCell = currentIndex + 1;
} else if (c == '\n') {
int startCell = holder.startCell;
cells[cellIndex++] = Arrays.copyOfRange(content, startCell, currentIndex);
holder.startCell = currentIndex + 1;
blackhole.consume(cells);
cellIndex = 0;
}
}
}
private Holder holder = new Holder();
static class Holder {
int startCell = 0;
}That still exhibit the weird behavior, the holder make it go faster.
Benchmark (nbCellsPerRow) (nbRows) Mode Cnt Score Error Units
SimplifiedBenchmark.benchmarkDirect 10 500000 sample 242 233.642 ± 9.727 ms/op
SimplifiedBenchmark.benchmarkHolder 10 500000 sample 327 169.661 ± 5.611 ms/opWhich is pretty good. We can see some of the logic of copyOfRange being put outside the condition check.
But the code is still quite complex to reason with. Does the loop matters? Is it just the if conditions.
isolate if condition
So next I wrote a version that isolates the if condition in a non-inlinable method. I also inline the char copy to make it easier for analysis.
@Benchmark
public void benchmarkDirect(CsvContent csvContent, Blackhole blackhole) {
char[] content = csvContent.content;
int startCell = 0;
for(int currentIndex = 0; currentIndex < content.length; currentIndex++) {
startCell = nextCharDirect(blackhole, content, startCell, currentIndex);
}
}
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
private int nextCharDirect(Blackhole blackhole, char[] content, int startCell, int currentIndex) {
char c = content[currentIndex];
if (c == ',') {
char[] chars = new char[currentIndex - startCell];
for(int i = 0; i < chars.length; i++) {
chars[i] = content[i + startCell];
}
blackhole.consume(chars);
startCell = currentIndex + 1;
} else if (c == '\n') {
char[] chars = new char[currentIndex - startCell];
for(int i = 0; i < chars.length; i++) {
chars[i] = content[i + startCell];
}
blackhole.consume(chars);
startCell = currentIndex + 1;
}
return startCell;
}the difference is not as striking there. one of the reason is that the copy logic is a lot simpler there is less code the sub here and some array instantiation preparation
being put outside the if.
But we still have the effect of having some code that should only execute conditionally being executed for each char.
Where do we go from there? we can see what happens but why would that be the case.
Everything is an illusion
The JIT can make a lot of optimisation, code that doesn’t need to be executed will be strip away, loops get unrolled, condition order changed depending on profiling stats. The ASM generated may look very different from your bytecode as long as the outcome is the same as the original code. That allows for a lot of optimisation to happens.
The JIT looks at the code in the form of an Abstract Syntax Tree and applies a list of transformation before generating the final machine code. And fortunately, there is a way to get an insight into what is happening (ht Jean-Philippe Bempel) with Ideal Graph Visualizer.
Unfortunately to be able to use that you need to build a debug version of OpenJDK.
Building OpenJDK
To build OpenJDK you will need a Linux box, on MacOsX it relies on an old version of Xcode that is not supported with Sierra.
Also, beware to not have a j in the name the path of the directories you are checking it out - avoid opendjdk -.
you will need JDK 1.7 to build it, it is also needed to launch ideal graph visualizer.
Make sure that you have a gcc 4.3 to 4.9 installed as it will fail with gcc 5 for ubuntu.
hg clone http://hg.openjdk.java.net/jdk8/jdk8 open_dk
cd open_dk
bash ./get_sources
bash configure --enable-debug --enable-openjdk-only --with-java-variants=server --disable-headful
# check that Boot JDK points to 1.7 and C and C++ compiler to Gcc 4.9
make allif it fails to check the os_versions because you are running a 4.x kernel append 4% to the SUPPORTED_OS_VERSION in hotspot/make/linux/Makefile
You might need to install a few libraries… but once make all succeed you have your vm in build/
Ideal Graph Visualizer
Now we need to start Ideal Graph Visualizer
wget http://ssw.jku.at/General/Staff/PH/igv_latest.zip
unzip igv_latest.zip
cd idealgraphvisualizer
bin/idealgraphvisualizer --jdkhome=/usr/lib/jvm/java-7-oracleand run the benchmark with the debug JVM
java -jar target/benchmarks.jar SimplifiedBenchmark2.benchmarkDirect -f 1 -i 10 -wi 10 -bm avgt -tu ms -jvm /home/aroger/dev/dev8/build/linux-x86_64-normal-server-fastdebug/jdk/bin/java -jvmArgs "-XX:PrintIdealGraphLevel=3"
java -jar target/benchmarks.jar SimplifiedBenchmark2.benchmarkHolder -f 1 -i 10 -wi 10 -bm avgt -tu ms -jvm /home/aroger/dev/dev8/build/linux-x86_64-normal-server-fastdebug/jdk/bin/java -jvmArgs "-XX:PrintIdealGraphLevel=3"the JVM might not be that stable and fail sometimes it should eventually run the benchmark successfully and you should see the nodes information being pushed to Ideal Graph Visualizer.
you can also export the data to a file using -XX:PrintIdealGraphFile=file.xml
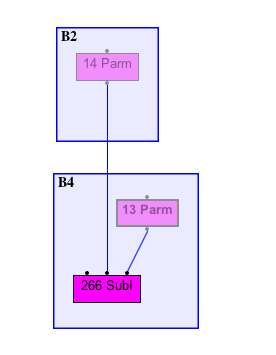
nextCharHolder graph
Let’s start by looking at the graph for the one with the holder.
If you look at ASM for the direct you see the length calculation
being done before the ',' check.
That sub is done after the if
in the holder version.
If we isolate the sub in the graph we can see that it depends on the if check.
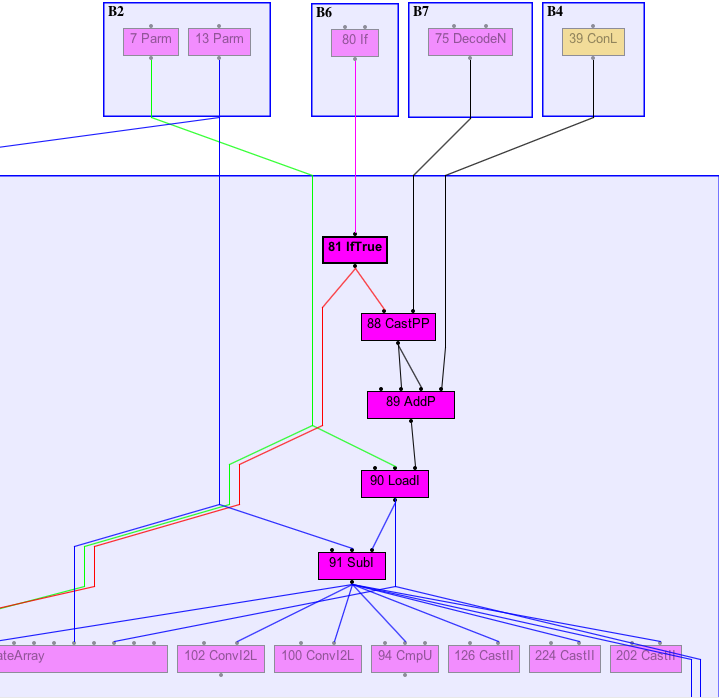
Same for the sub in the second condition
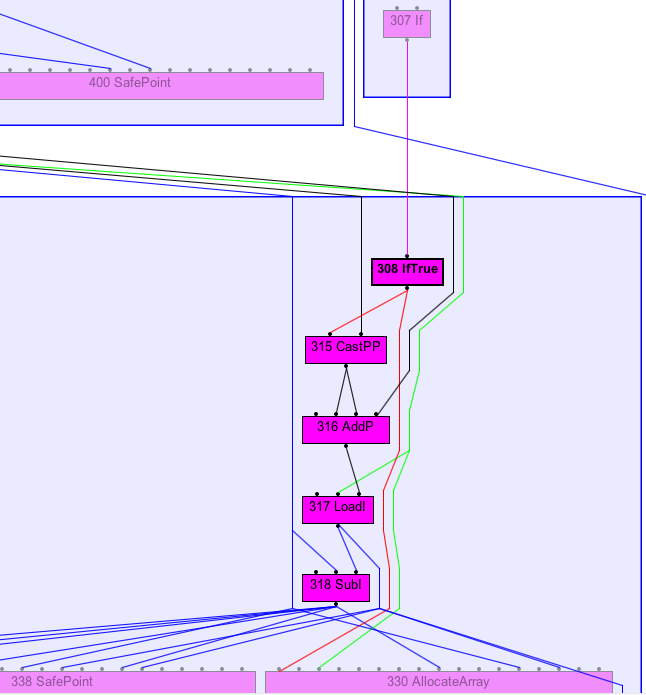
That stays true after the RemoveUseless in the AfterParsing stage
see the following graphs.
{kind=link}
{kind=link}
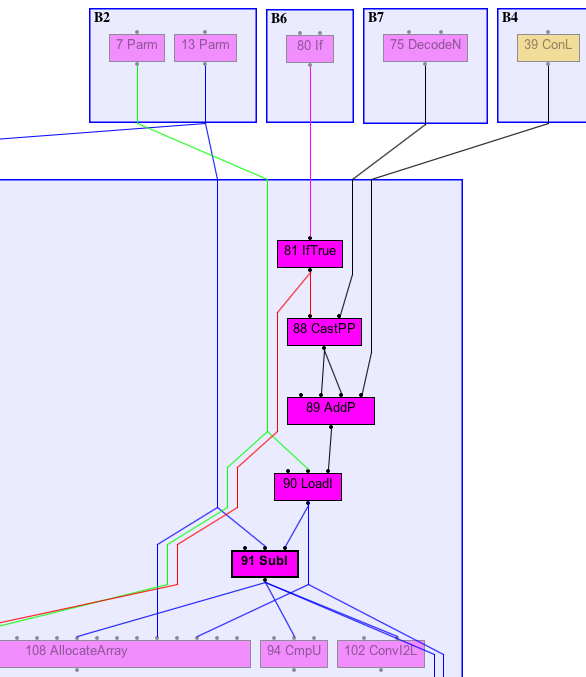
nextCharDirect graph
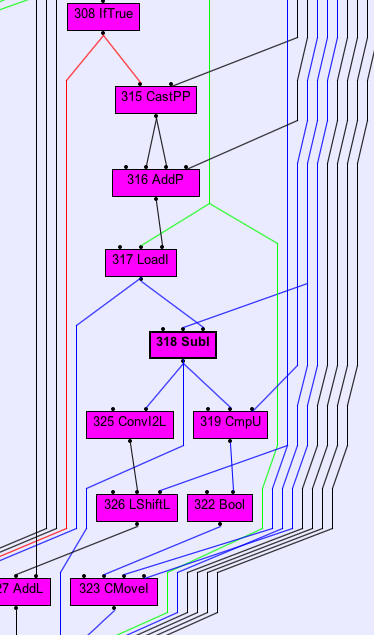
But in the direct call we can see the 2 subs in the Before RemoveUseless stage
there is no dependency on the If
-
for the
','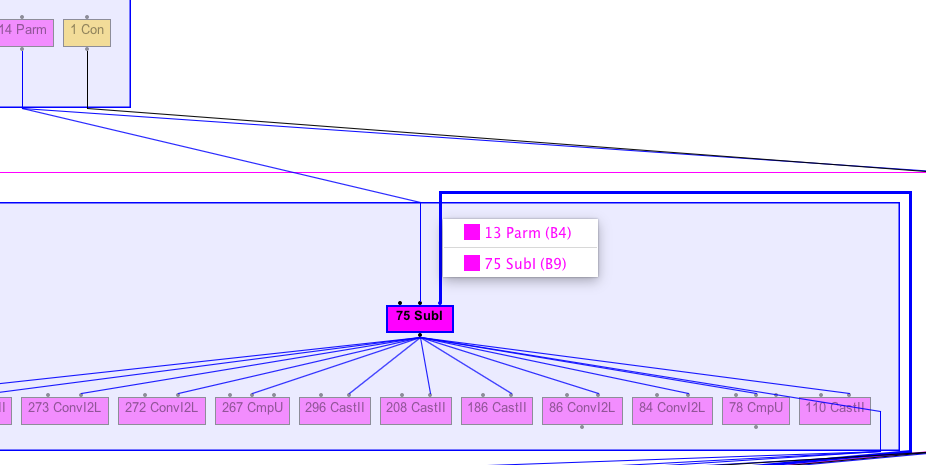
-
or the
'\n'
And at the AfterParsing stage, there is only one Sub left
The allocated array depends on the Sub and on the If, but the Sub does not depend on the If.
Which can explain why it is pushed outside the If.
What does that mean?
Because the sub does not depend on the if in the direct call in the RemoveUseless stage and does not have any side effect
the code get consolidate in one place and is generated outside the if.
The holder stops that by creating a dependency on the if. Why does it create a dependency on the if?
I don’t know yet.
When is it a problem?
If you have a 2 or more test that contains duplicated code with no side effect, that code might end up being executed outside the if.
Depending on the condition ratio and how many time the if is called, the impact might start to dominate as it does in my
CSV parser. Most of the time the condition are false and the code inside should not be executed but some of it is.
What next?
I would really like to understand why SubI does not depend on if but when adding an indirection it does.
How does the RemoveUseless work? should the code with no side effect still be marked as depending on the if.
The only place to go from there is to dig in the hotspot code … and experiment in will
hopefully be part 3.