Revisiting File InputStream and Reader instantiation.
A few days ago I cam across a tweet from @leventov about that Hadoop bug report.
Because FileInputStream implements a finalize method it creates quite a bit of pressure on the Garbage Collector.
You can use the FileChannel to read directly in a ByteBuffer, but we will focus only on the InputStream in place replacement.
How do you avoid FileIntputStream
As stated in the bug report, you need to go through a FileChannel, then you can create an InputStream using Channels.newInputStrean(ch).
That’s also what the convenience method Files.newInputStream end up doing.
try (FileChannel channel = FileChannel.open(file.toPath())) {
try (InputStream is = Channels.newInputStream(channel)) {
// do something
}
}
try (InputStream is = Files.newInputStream(file.toPath)) {
// do something
}
If you are stuck in java 6 you will need to get the FileChannel via a RandomAccessFile.
RandomAccessFile randomAccessFile = new RandomAccessFile(file, "r");
try {
FileChannel channel = randomAccessFile.getChannel();
try {
InputStream is = Channels.newInputStream(channel);
try {
// do something
} finally {
is.close();
}
} finally {
channel.close();
}
} finally {
randomAccessFile.close();
}
Those will return a sun.nio.ch.ChannelInputStream which does not define a finalizer.
which one is faster?
There are 2 effects at play there, one is the GC pressure impact, and the other one it the difference in byte reading.
let’s write a small jmh benchmark that reads the content of a file using the different InputStream.
FileInputStreamtry (FileInputStream is = new FileInputStream(file)) { consume(is, blackhole); }Files.newInputStreamtry (InputStream reader = Files.newInputStream(file.toPath())) { consume(reader, blackhole); }RandomAccessFiletry (RandomAccessFile randomAccessFile = new RandomAccessFile(file, "r")) { try (FileChannel open = randomAccessFile.getChannel()) { try (InputStream inputStream = Channels.newInputStream(open)) { consume(inputStream, blackhole); } } }FileChanneltry (FileChannel open = FileChannel.open(file.toPath())) { try (InputStream is = Channels.newInputStream(open)) { consume(is, blackhole); } }
And we will run that on a 16, 4k, 32k, 500 000 bytes, and 5 000 000 bytes file.
The full results.
If we plot the chart as different in % from the FileInputStream
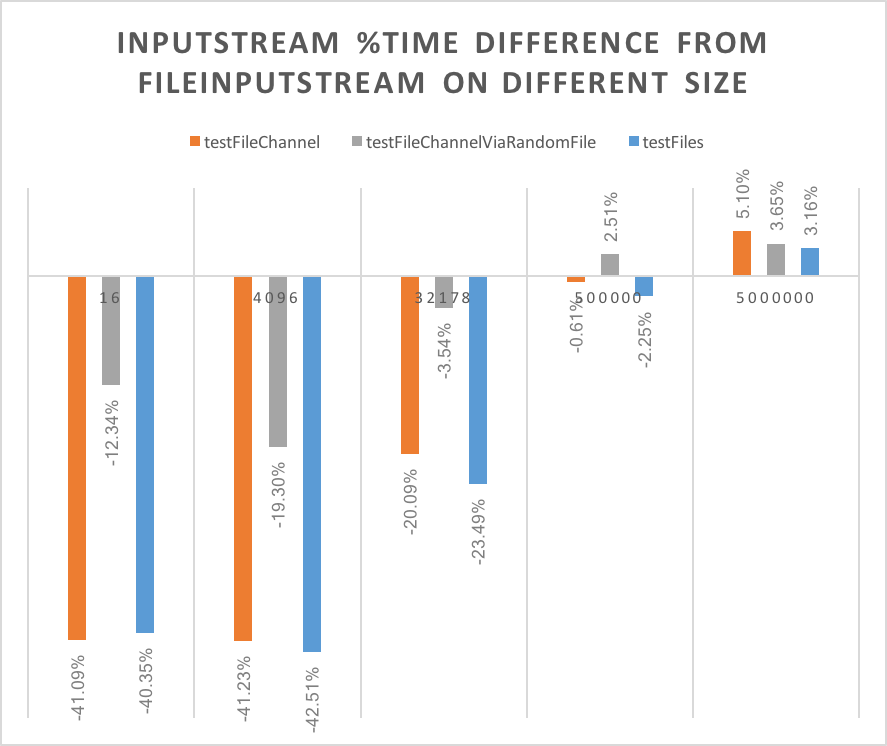
We can see that for small files 16, to 32k there are clear benefits in using the FileChannels, but as the size grows the performance converges to FileInputStream, even getting slightly slower.
Also for big files, FileInputStream is better, Files.newInputStream gives far better results on small files and is pretty close on big files.
What about Reader?
To instantiate a Reader without a FileInputStream we will use the FileChannel
try (FileChannel channel = FileChannel.open(file.toPath())) {
try (Reader reader = Channels.newReader(channel, "UTF-8")) {
// do something
}
}
or in java6
RandomAccessFile randomAccessFile = new RandomAccessFile(file, "r");
try {
FileChannel channel = randomAccessFile.getChannel();
try {
Reader reader = Channels.newReader(open, "UTF-8");
try {
// do something
} finally {
reader.close();
}
} finally {
channel.close();
}
} finally {
randomAccessFile.close();
}
You could also user an InputStreamReader on top of a ChannelInputStream.
try (InputStream is = Files.newInputStream(file.toPath)) {
try (Reader reader = new InputStreamReader(is, "UTF-8")) {
// do something
}
}
which one is faster
Here we go for another jmh benchmark With the following strategies
- testFiles ->
Files.newBufferedReader - testFileChannelViaRandomFile ->
Channels.newReader(new RandomAccessFile(file, "r").getChannel()) - testFileChannel ->
Channels.newReader(FileChannel.open(file.toPath()), "UTF-8") - testInputStreamReaderFromChannelInputStream ->
new InputStreamReader(Files.newInputStream(file.toPath()), "UTF-8") - testFileInputStream ->
new InputStreamReader(new FileInputStream(file), "UTF-8")
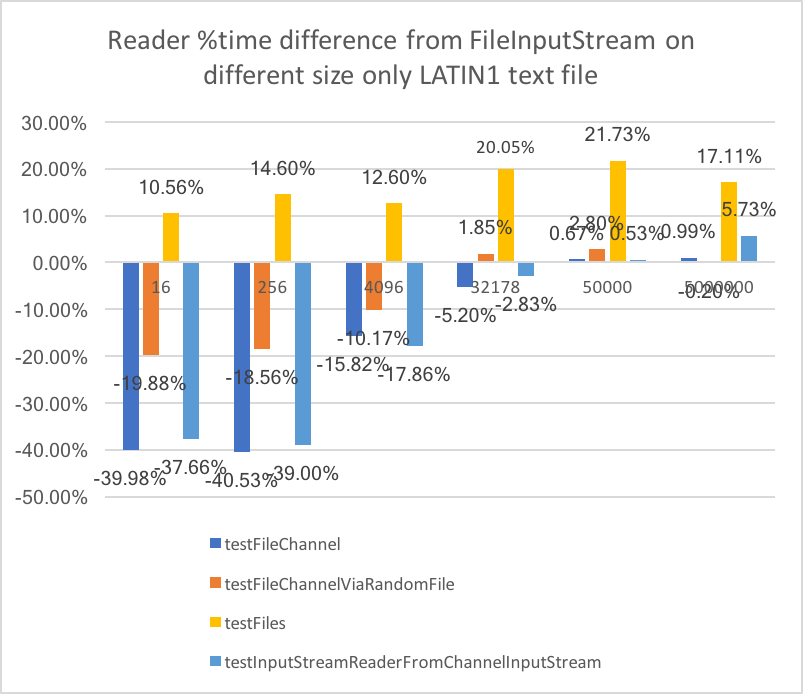
We run the benchmark against a file with latin1 characters and one with Japanese characters.
Latin1 :
Japanese :
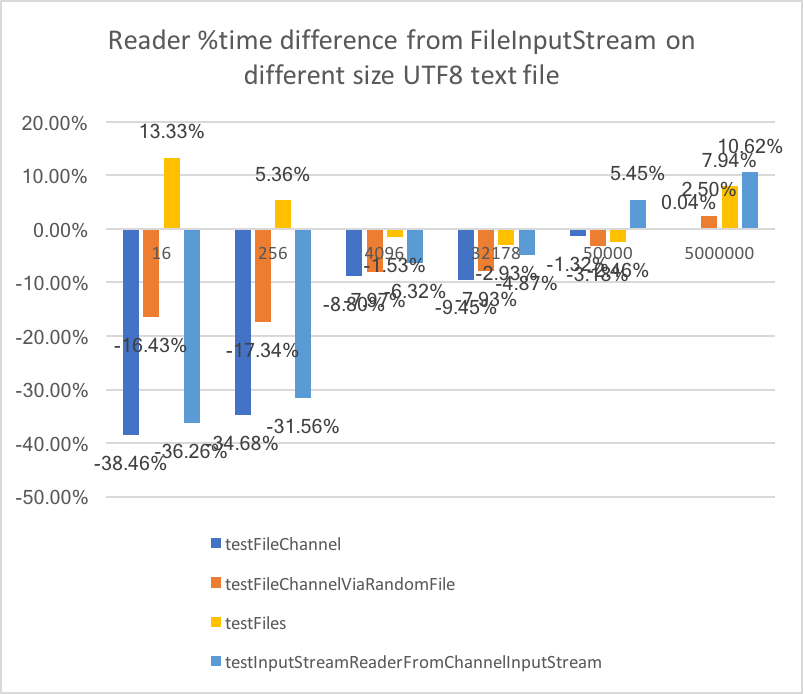
And the winner is the testFileChannel strategy that is 30-40% faster on small file and equivalent in perf on big files.
Summary
So it seems that for InputStream it can be worth moving to Files.newInputStream
and for Reader it is definitely worth using the Channels.newReader(FileChannel.open(file.toPath()), "UTF-8") strategy.
To go further it would be interesting to isolate what part of the performance difference is linked to the GC pressure and what part is linked to the difference in implementation.
The benchmark seems to be consistent between Ubuntu and MacOSX.
PS: java9 returns similar results, except for InputStream FileInputStream is 4 to 8% faster on the big file size. but reader conclusions are the same.